由于对大数据处理的需求。使得我们不断扩展计算能力,集群计算的要求导致分布式计算框架的诞生。用便宜的集群计算资源在短短的时间内完毕以往数周甚至数月的执行等待,有人说谁掌握了庞大的数据。谁就主导了需求。尽管在十几年间,通过过去几十年的积淀,诞生了mapreduce。诞生了分布式文件系统。诞生了霸主级别的Spark,不知道这是不是分布式计算框架的终点,假设还有下一代的处理框架,必定来自更大规模的数据。我想那个量级已经不是今天能够想象的。先研究好当前的,走得越深。看得越深,所以诞生Spark的地方是在AMPLab,而不是一家互联网电商巨头。
不可变基础设施
干货链接
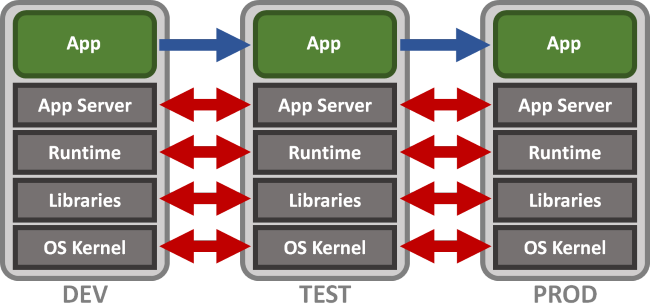
我们在本地用Eclipse Scala或者IntelliJ IDEA编写好Spark程序后,须要对其进行測试,在測试环境下。我们部署好了执行Spark所需的 Software Stack,并特别注意各个Software的版本号。
那假设有人想用这个程序。在他的环境下,是不同的Software Stack,那么程序就有可能失败。假如我们想要在不论什么机器上不费力气的部署和执行我们所开发的Spark程序,我们使用Docker将操作系统和Software Stack打成一个镜像包,让这个镜像包成为一个不可变单元,那么在不论什么机器上我们仅仅要部署好这个镜像的演示样例,所开发的Spark应用程序便可成功执行。
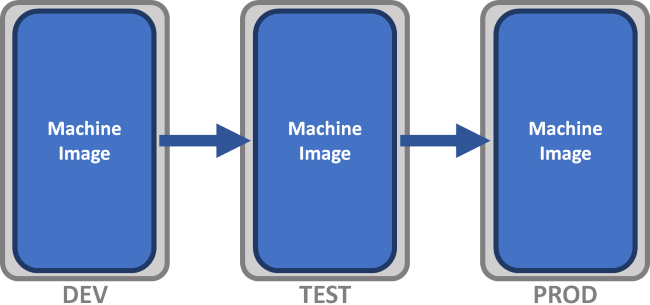
以下的图出自上面第二个链接,第二个图就表述了不可变基础设施,第一个是传统的DevOps环境。
Tachyon
Spark on Yarn
—— 可与 3 形成參考
—— 推荐
以下是阿里云梯给出的Spark on YARN架构图
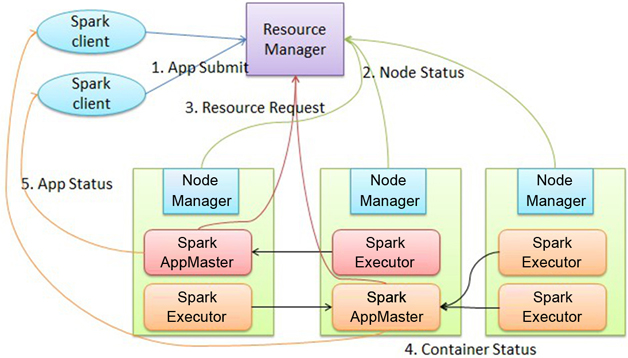
“基于YARN的Spark作业首先由client生成作业信息。提交给ResourceManager。ResourceManager在某一 NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动 SparkAppMaster,SparkAppMaster启动后初始化作业。然后向ResourceManager申请资源。申请到对应资源后 SparkAppMaster通过RPC让NodeManager启动对应的SparkExecutor,SparkExecutor向 SparkAppMaster汇报并完毕对应的任务。此外,SparkClient会通过AppMaster获取作业执行状态。
”
上面的信息来自
是一篇不错的干货1) 配置Hadoop Yarn集群时出现的问题及修复:
在每一台机器上(master和各个slave),都要对hadoop-env.sh和yarn-env.sh两个文件末尾加入(export)JAVA_HOME这个环境变量(依据详细机器上JAVA_HOME的不同而不同)。
在经过
cd ~/hadoop-2.7.1 #进入hadoop文件夹bin/hadoop namenode -format #格式化namenodesbin/start-dfs.sh #启动dfs sbin/start-yarn.sh #启动yarn
之后。登录 ,发现有slave节点是unhealthy状态,再进行一下配置,在每台机器(master和各个slave)上。改动yarn-site.xml文件,加入例如以下:(不推荐!
)
name=yarn.nodemanager.disk-health-checker.enable
value=false
然后在master上stop-all.sh后。又一次启动集群:
sbin/start-dfs.sh #启动dfs sbin/start-yarn.sh #启动yarn
就会发现恢复正常。
2) 配置spark的spark-env.sh时
注意master上SPARK_LOCAL_DIRS的值和各个slave上应当一样,即spark放在各个机器的同一路径下。
3) 眼下来看在REHL 7.1上编译成的hadoop并不能在SUSE上跑起来
4) 各种slaves文件里不加入localhost这一项。假设不想让master机器也成为worker參与集群运算的话。
Hadoop 编译
干货推荐
【1】 安装mvn
【2】安装JAVA,环境变量设置
以 root 用户 vi /etc/profile 或者 vi ~/.bashrc依据自己路径在最后加入以下三行#jdkexport JAVA_HOME=/usr/java/jdk1.7.0_67 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin 加入之后执行 source /etc/profile 或者source ~/.bashrc
【3】 安装google的protobuf
a. (推荐) b. (參考)检查是否成功安装 protoc –version
【4】下载源代码编译
编译命令
mvn clean package -Pdist,native -DskipTests -Dtar
Hadoop 编译出错
我是在IBM JAVA环境下进行hadoop的编译。列出编译过程中的错误和解决方法。供大家參考。
1) Antrun
Failed to execute goal
org.apache.maven.plugins:maven-antrun-plugin:1.6:run (create-testdirs)
chown -R username parent-directory( 如 chown -R root ../ )mvn install -DskipTests
2) Build failed with JVM IBM JAVA on TestSecureLogins
package com.sun.security.auth.module does not exist
这是专门为在IBM JAVA环境下打的patch。
3) 经过上面两个fix后假设非常快显示BUILD SUCCESS。并且在(假设下载的源代码文件夹名为hadoop-release-2.7.1)hadoop-release-2.7.1/hadoop-dist/target/文件夹下没有名为hadoop-2.7.1.tar.gz的tar包。说明没有编译成功,返回到hadoop-release-2.7.1这个根文件夹下。继续执行:
mvn package -Pdist -DskipTests -Dtar
这之后编译的时间明显变长。各位在这段惊心动魄的时间里度过吧:)
YARN集群执行SparkPi出错
在 yarn-cluster 模式下
WARN hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block BP-xxx:blk_1073741947_1123java.io.IOException: Bad response ERROR_CHECKSUM for block BP-xxx:blk_1073741947_1123 from datanode xxxxx:50010
Exception in thread “main” java.io.IOException: All datanodes
xxxxx:50010 are bad. Aborting… at org.apache.hadoop.hdfs.DFSOutputStream DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1206) at org.apache.hadoop.hdfs.DFSOutputStream DataStreamer.processDatanodeError(DFSOutputStream.java:1004) at org.apache.hadoop.hdfs.DFSOutputStream DataStreamer.run(DFSOutputStream.java:548)
上述错误是由于IBM大型机上大小端的问题,须要一个。
或者通过组合异构平台解决(引入x86机器)。只是假设要让大机作为worker进行运算就要打上patch。
执行成功显示:
Spark standalone master单节点执行时出错
假设分配给spark的driver内存 SPARK_DRIVER_MEMORY(在spark-env.sh中设置)不足。比方仅仅设置了1G,非常有可能出现以下的错误,我改成20G后就能够避免。不足的话。GC会做大量的清扫工作,不仅极大的消耗CPU,并且会出现执行失败。
16/01/24 09:59:36 WARN spark.HeartbeatReceiver: Removing executor driver with no recent heartbeats: 436450 ms exceeds timeout 120000 ms16/01/24 09:59:40 WARN akka.AkkaRpcEndpointRef: Error sending message [message = Heartbeat(driver,[Lscala.Tuple2;@3570311d,BlockManagerId(driver, localhost, 54709))] in 1 attemptsorg.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [120 seconds] at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219) at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223) at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107) at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53) at scala.concurrent.Await$.result(package.scala:107) at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcEnv.scala:241)
16/01/24 09:59:40 ERROR scheduler.TaskSchedulerImpl: Lost executor driver on localhost: Executor heartbeat timed out after 436450 ms
Exception in thread "main" 16/01/24 10:06:49 INFO storage.BlockManagerMaster: Trying to register BlockManagerorg.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 10.0 failed 1 times, most recent failure: Lost task 0.0 in stage 10.0 (TID 6, localhost): ExecutorLostFailure (executor driver lost)
Spark对内存的消耗主要分为三部分(即取决于你的应用程序的需求):
- 数据集中对象的大小
- 訪问这些对象的内存消耗
- 垃圾回收GC的消耗
由网络或者gc引起,worker或executor没有接收到executor或task的心跳反馈,导致 Executor&Task Lost。这时要提高 spark.network.timeout 的值,依据情况改成300(5min)或更高。
yarn-cluster模式执行出错

由于所执行的程序须要第三方jar,而没有引入导致。
解决: 使用 –jars 和 –archives加入应用程序所依赖的第三方jar包,如spark-submit --class spark-helloworld --master yarn-cluster --jars scopt.jar spark-helloworld.jar
同一时候检查资源分配參数的设置。以防由于资源分配不够导致执行失败。
MapReduce:大数据理论基石
现在的阿里飞天系统能够超越一台超算。
超大规模分布式计算浪潮不可阻挡,大数据处理刚刚開始。一些东西在达到一定规模后就会出现前所未有的难题,在理论上或许无法预见,复杂度和不可预知性在添加,技术进步就会出现。
MapReduce编程模型由map和reduce两个核心函数构成。
Map:将原始输入转换成一个个key/value的键值对形式的描写叙述。同一key下可能有多个value。然后传给Reduce。
Reduce:将同一key下的value进行合并,让value的集合缩小。
我们常常在linux上使用grep命令来帮我们找出一个输出中我们想要的字段,假设它也变成分布式的话,我们就能够利用多台机器从庞大的输出或文件里找到我们想要的字段,那么这个map函数就是将我们想要的字段利用grep从输出中找出来,而reduce负责将每台机器上这种grep后的输出进行汇总就是全部的我们想要的字段了。
以下是MapReduce论文里的架构图:
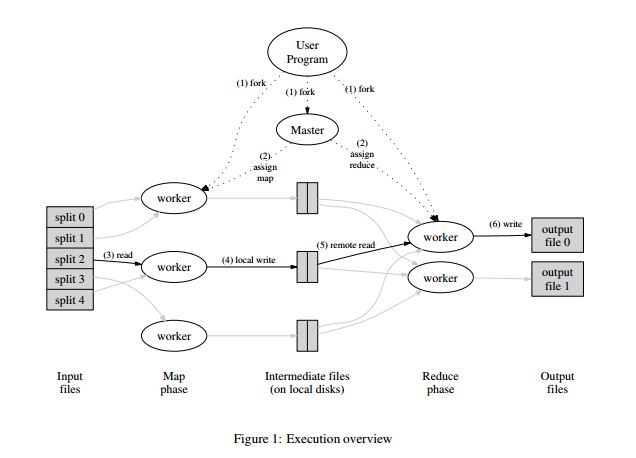
User program会创建非常多worker,这些worker中有一个是master。负责将map任务分配给哪些worker。将reduce任务分配给另外一些worker。负责map的worker会读取原始文件(已经被分成一份份的)进行map操作。生成的中间键值对结果会从内存中转移到硬盘上。在master的通知下。负责reduce的worker就会知道从硬盘的某个地方读取到这些中间结果从而进行reduce操作生成终于的output。